Inter-agent Transfer Learning in Communication-constrained Settings
Researcher(s):
- Argha Boksi
- Balaraman Ravindran
Description:
Deep reinforcement learning algorithms have shown promise in addressing complex decision-making problems, but they often require millions of steps of suboptimal performance to achieve satisfactory results. This limitation restricts the application of Deep RL in many real-world tasks, where agents cannot afford to rely on thousands of learning trials, particularly when each suboptimal trial is costly. The teacher-student framework seeks to enhance the sample efficiency of RL algorithms. In this setup, a teacher agent guides another student agent’s exploration by providing advice on the optimal actions to take in specific states. However, in numerous applications, communication is constrained by factors such as available bandwidth or battery power. In this paper we consider a student-initiated advising approach where the student can query the teacher only a predetermined fixed number of times.
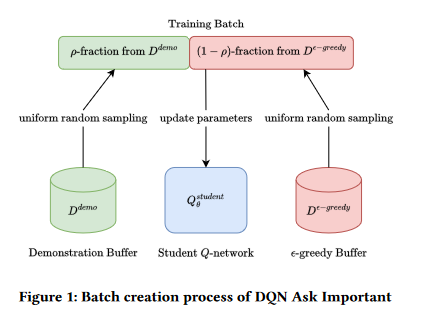
We introduce a frame-work, Ask Important that -
(a) ensures effective utilization of the limited advice budget by querying the teacher only in important states
(b) makes efficient use of the collected demonstration data by introducing an additional demonstration buffer.
Ask Important framework can be utilised by RL algorithms(which work with discrete action spaces and leverage a replay buffer to store and sample experiences) such as DQN, Double DQN, Dueling DQN etc. We explain how Ask Important can be integrated within the DQN algorithm. We compare DQN Ask Important with – DQN(baseline) and an ablation of our method. We evaluate these algorithms in three Gymnasium environments – Acrobot-v1, MountainCar-v0 and LunarLander-v2.
The results show that DQN Ask Important –
(a) has better initial performance
(b) reaches the target average episodic return much faster – than the other two algorithms for all the three environments.