Explainable RL Using Causal Inference
Researcher(s):
- Devika Jay
Collaborators:

Description:
Motivation
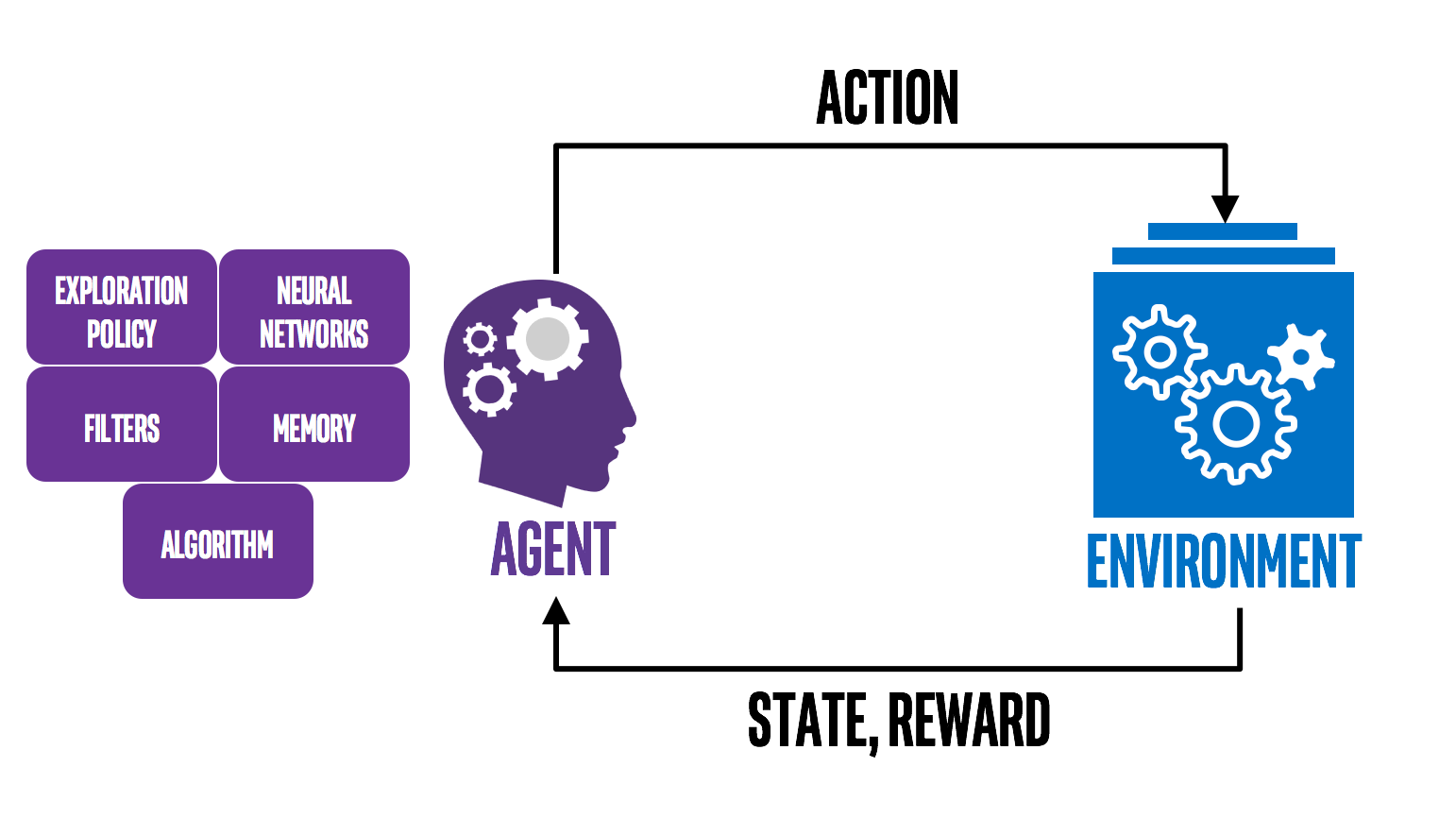
Explain the behaviour of agents during data-drift scenarios when the agent is deployed online after being trained using offline RL techniques.
-
Trajectory explanations to adjust the noise generated due to simulator-based RL.
-
Trajectory explanations that are robust in handling the difference between the observed trajectory and predicted trajectory on long-term
-
The mechanism of learning of the causal model in cases where learning post-hoc may require access to the original training environment
Deployment
The roll- out trajectories from the trained RL agent are passed through the ‘Explainer’ module.
The ‘Explainer’ module presents abstract explanations which can be then passed through LLM modules for natural language explanations.
Applications
Antenna tilt optimisation: MARL agent is deployed for achieving the optimal tilt of antenna across all nodes in a 5G network considering multiple operation constraints. The trajectory of the antenna achieved using the MARL agent is to be explained.

Intent management: Building trustworthiness of the MARL agent deployed for optimal resource allocation that will maximise the intent utility function.